cnn可视化与理解(1)—cnn每一层在找什么
2016-06-01
前言
虽然神经网络近年来取得了巨大的成功,但神经网络的中间层却一直被视为”黑盒”一样的存在,这造成了外界对神经网络的各种误解,所以近两年学界对中间层的探索做了大量的工作。对于cnn卷积网络而言,从2013年的Visualizing and Understanding Convolutional Networks开始,人们对卷积网络的可视化和理解进行了很多实验,开发了很多工具。而作为机器学习工程师,只有理解了中间层的作用才能更好的进行网络架构的设计
1. CNN卷积层可视化
本部分内容参考Zeiler 和 Fergus的论文和CS231N内容
 上图是ALexNet的第一层原生weight(96x55x55)的直接可视化,每一个单元格都代表了一个卷积核(55x55),可以从上图中看出每一个卷积核都在寻找一个小的简单结构,包括不同角度的线,不同大小的圆和不同的色块等等.我们也可以直接把第二三四等层的卷积核如上图一样直接可视化,但是这些高层的原生weight或者filter是难以理解和解释的.
上图是ALexNet的第一层原生weight(96x55x55)的直接可视化,每一个单元格都代表了一个卷积核(55x55),可以从上图中看出每一个卷积核都在寻找一个小的简单结构,包括不同角度的线,不同大小的圆和不同的色块等等.我们也可以直接把第二三四等层的卷积核如上图一样直接可视化,但是这些高层的原生weight或者filter是难以理解和解释的.
既然原生的filter难以理解,我们必须绕道去观察,其中Deconv approaches让不同的图片通过一个训练好的模型的卷积层,观察其变化,以此探索这些卷积层在寻找什么.它的原理如下:
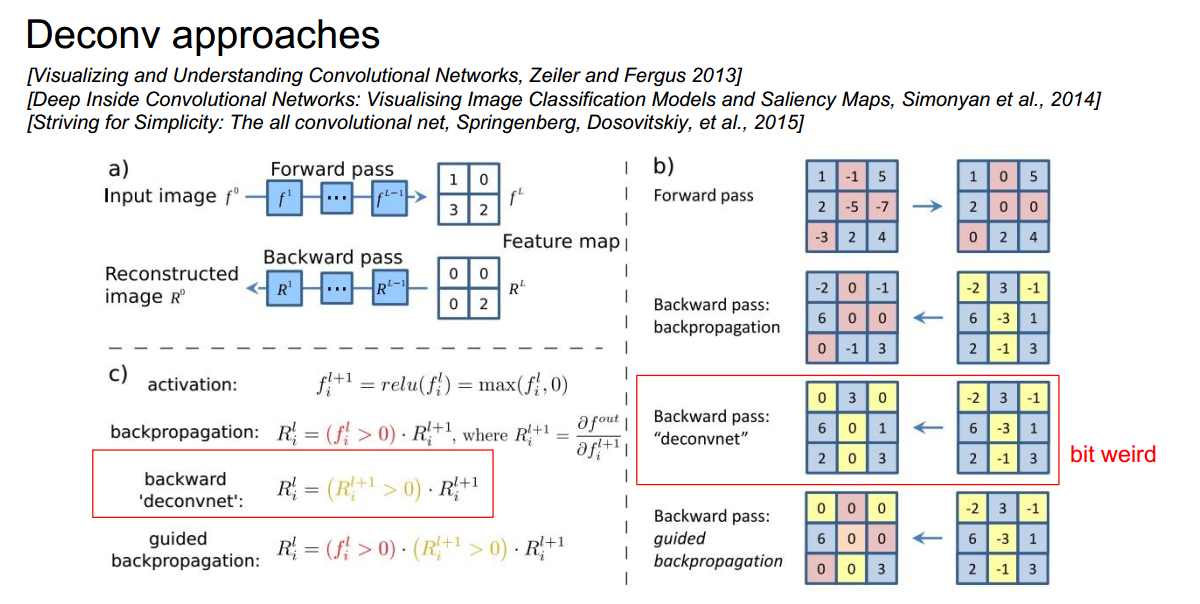 我们输入一张图片,让它通过网络直到我们想观察的那一层,然后把该层我们想观察的神经元的梯度置为1,其他神经元的梯度置为0,从该层开始反向传播,但是在反向传播时要做出一点改变:
我们输入一张图片,让它通过网络直到我们想观察的那一层,然后把该层我们想观察的神经元的梯度置为1,其他神经元的梯度置为0,从该层开始反向传播,但是在反向传播时要做出一点改变:
1 backword deconvnet方法把反向传播中的所有梯度小于0的,全置为0,如图红框中所示
2 guided backpropagatin方法除了把反向传播中梯度小于0的置为0外,还把前向传播中小于0的单元也置为0,事实上这种方法产生的效果要更好一点
这样做的原因是反向传播中负的部分会对我们想得到的图片产生消极影响,从而使图片难以理解,只保留正的部分可以使图片容易观察.
下面的图片采用的是backword deconvnet方法得到的,可以看到也可以取得不错的效果.
1.1 layer1
 上图的每个格子同样代表一个卷积核,对于第一行第一列的格子可以粗略看出一条-45度直线,事实上这个格子的卷积核寻找的正是-45度左右的线条,它会对如下图片产生激活反应:
上图的每个格子同样代表一个卷积核,对于第一行第一列的格子可以粗略看出一条-45度直线,事实上这个格子的卷积核寻找的正是-45度左右的线条,它会对如下图片产生激活反应:
 对于第三行第三列的格子而言,它寻找的是类似下图的色块
对于第三行第三列的格子而言,它寻找的是类似下图的色块
 所以总体来说对于一个训练好的模型来说,它的第一层总是在寻找这些简单的结构,不管是AleNet,ResNet还是DenseNet
所以总体来说对于一个训练好的模型来说,它的第一层总是在寻找这些简单的结构,不管是AleNet,ResNet还是DenseNet
1.2 layer2
 可以看到输入相应图片后,网络激活输出了稍复杂的纹理结构,比如条纹(第一行),嵌套的圆环(第二行右面),色块等等。
可以看到输入相应图片后,网络激活输出了稍复杂的纹理结构,比如条纹(第一行),嵌套的圆环(第二行右面),色块等等。
1.3 layer3
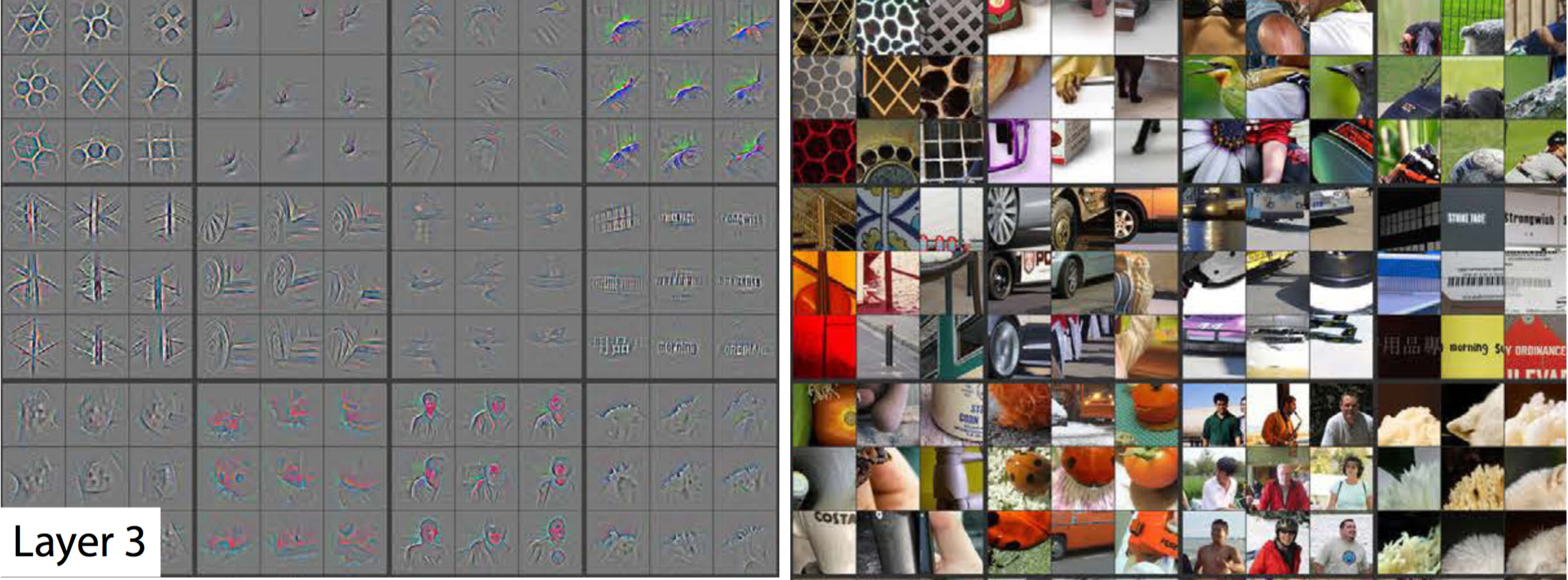 第三层输出了第二层的组合,比如蜂巢,人,门窗和文字的轮廓
第三层输出了第二层的组合,比如蜂巢,人,门窗和文字的轮廓
1.4 layer4
 第四层,我们开始得到一些真实物品形状的东西,例如狗,准确说是狗的抽象形状
第四层,我们开始得到一些真实物品形状的东西,例如狗,准确说是狗的抽象形状
1.5 layer5
 第五层,我们得到一些更高层次的抽象,比如右边第8行4列穿红衣服的女人,输出的是人脸部分,因为对于分类来说,神经网络使用人脸来区分图像是不是表示一个人,所以它只关心人脸部分
第五层,我们得到一些更高层次的抽象,比如右边第8行4列穿红衣服的女人,输出的是人脸部分,因为对于分类来说,神经网络使用人脸来区分图像是不是表示一个人,所以它只关心人脸部分
有一个类似的交互性的工作,视频和网址,可以实时的看到网络每一层对输入的反应.
2. last layer
对于最后一层,也就是分类层也无法直接对weight进行观察的,不过可以通过降维的方法比如PCA或t-SNE,把它映射到2维平面上,如下图所示:
 该图片是对0-9数字的分类任务的最后一层的映射,我们把大量的图片输入网络,在最后一层得到28*28的高维特征,然后降维到2维平面.可以很明显的看到同类的特征会自动聚集到一起,而类与类之间会分离,也就是分类任务已经完成
该图片是对0-9数字的分类任务的最后一层的映射,我们把大量的图片输入网络,在最后一层得到28*28的高维特征,然后降维到2维平面.可以很明显的看到同类的特征会自动聚集到一起,而类与类之间会分离,也就是分类任务已经完成
3. 总结
这些激活是CNN自己学会的,或者说当我们定义相应loss函数,并用反向传播倒逼其收敛时,cnn每一层的filter会不断调整自己,直到它具有上述能力。
从这里我们也可以想象出过拟合的现象,那就是若过拟合则每层的激活对训练集来说更精准,但适应性也更差.
这是对网络单层的探索,为了解开黑盒,还有很多其他的方法,在下一篇文章中会用实际代码展示这些方法.